I came across this question on interview street:
Random number generator
There is an ideal random number generator, which given a positive integer M can generate any real number between 0 to M with equal probability.
Suppose we generate 2 numbers x and y via the generator by giving it 2 positive integers A and B, what’s the probability that x + y is less than C? where C is a positive integer.
Input Format
The first line of the input is an integer N, the number of test cases.
N lines follow. Each line contains 3 positive integers A, B and C.
All the integers are no larger than 10000.
Output Format
For each output, output a fraction that indicates the probability. The greatest common divisor of each pair of numerator and denominator should be 1.
Input
3
1 1 1
1 1 2
1 1 3
Output
1/2
1/1
1/1
One way to consider this problem is by generating functions. Suppose the distribution is not uniform, is there any efficient way to compute the probability that the sum of the two randomly generated numbers is no greater than 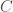 ?
?
Suppose for the first random number generator, the probability of that the randomly generated number,  , equals to
, equals to 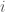 , is
, is  , for
, for  , and similarly, for the second random generator, the probability that the randomly generated number
, and similarly, for the second random generator, the probability that the randomly generated number 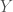 is is
is is  ,
,  Define two polynomials
Define two polynomials  and
and  . Then consider the multiplication of
. Then consider the multiplication of  :
:
 ,
,
The  coefficient in the right hand side of the above equation is precisely the probability of
coefficient in the right hand side of the above equation is precisely the probability of  . So the probability that
. So the probability that  is the summation of the first
is the summation of the first  terms. In the problem of interview street, since the distribution is uniform, each is
terms. In the problem of interview street, since the distribution is uniform, each is  , and each is
, and each is  . So we can easily obtain the probability that
. So we can easily obtain the probability that  .
.
The probability puzzle (using generating functions) is the following:
Loaded dice: No matter what two loaded dice we have, it cannot happen that each of the sums 2,3, …, 12 comes up with the same probability.
(I first came across this puzzle from the book “The art of mathematics”).
We can reason like this: let denotes the probability that the result of the first dice is , for  . Similarly, let denotes the probability that the result of the second dice is , . Then the probability that the sum of the two results is
. Similarly, let denotes the probability that the result of the second dice is , . Then the probability that the sum of the two results is 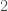 is
is  (the first dice and second dice must both output 1). The probability that the sum is 12 is
(the first dice and second dice must both output 1). The probability that the sum is 12 is  (both dices must output 6). Then consider the probability that the sum is 7: it is at least
(both dices must output 6). Then consider the probability that the sum is 7: it is at least  (the first dice outputs 1, and the second dice outputs 6, or the reverse). But
(the first dice outputs 1, and the second dice outputs 6, or the reverse). But  .
.
This reasoning works, but the book provides a much better proof using generating functions. As before, let  and let
and let  . Now if the sums 2,3,…,12 comes with the same probability, 1/11, then we have
. Now if the sums 2,3,…,12 comes with the same probability, 1/11, then we have
 . Now since both
. Now since both  and
and  are polynomials of degree 5,
are polynomials of degree 5,  has real roots; however, the right hand side is a cyclotomic polynomial which does not have any real root. Thus the identity cannot hold.
has real roots; however, the right hand side is a cyclotomic polynomial which does not have any real root. Thus the identity cannot hold.
Here is another application of generating functions for computing probabilities.
Counting heads Given integers  and
and 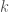 , along with
, along with ![p_1, ..., p_n \in [0,1]](https://s0.wp.com/latex.php?latex=p_1%2C+...%2C+p_n+%5Cin+%5B0%2C1%5D&bg=fff&fg=444444&s=0&c=20201002) , you want to determine the probability of obtaining exactly heads when biased coins are tossed independently at random, where is the probability that the
, you want to determine the probability of obtaining exactly heads when biased coins are tossed independently at random, where is the probability that the  coin comes up head. Assume that you can multiply and add two numbers in
coin comes up head. Assume that you can multiply and add two numbers in ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=fff&fg=444444&s=0&c=20201002) in
in  time.
time.
(This problem is from this book.)
This problem can be solved using dynamic programming: Let  be the indicator random variable for the event that the result of tossing
be the indicator random variable for the event that the result of tossing  coin is head, for
coin is head, for  . Notice that
. Notice that
 .
.
The time complexity is  . However, if we consider the approach generating functions, we can get a faster algorithm using fast fourier transform:
. However, if we consider the approach generating functions, we can get a faster algorithm using fast fourier transform:
Let  , for . Then consider the product of the polynomials of degree 1:
, for . Then consider the product of the polynomials of degree 1:  . The probability of obtaining heads is the coefficient
. The probability of obtaining heads is the coefficient  . Therefore, the problem is reduced to how fast we can multiply polynomials. Using fast fourier transform, we can multiply two polynomials of degree at most in time
. Therefore, the problem is reduced to how fast we can multiply polynomials. Using fast fourier transform, we can multiply two polynomials of degree at most in time  . Hence, we can use divide-and-conquer to multiply these polynomials:
. Hence, we can use divide-and-conquer to multiply these polynomials:
 .
.
Let 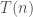 denotes the time to multiply polynomials of degree 1. Then we have the following recursion:
denotes the time to multiply polynomials of degree 1. Then we have the following recursion:
 ,
,
as in the “conquer” step, we are multiplying two polynomials of degree  . Hence
. Hence  .
.



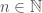








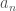






















 be a shape in the plane with area
be a shape in the plane with area  . Prove that it is possible to place
. Prove that it is possible to place  coordinates and
coordinates and 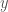 coordinates are both integers.
coordinates are both integers. and shifting the integer lattice according to the vector, the expected number of integer lattice point contained in
and shifting the integer lattice according to the vector, the expected number of integer lattice point contained in  . If the area of
. If the area of  ? The final seating situation is one of the following cases: [1, 2, 3] or [2, 1, 3] or [2, 3, 1] or [3, 2, 1]. The sequence
? The final seating situation is one of the following cases: [1, 2, 3] or [2, 1, 3] or [2, 3, 1] or [3, 2, 1]. The sequence  denotes that the
denotes that the 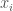 . So the probability that the last passenger sits on his own seat is still 1/2.
. So the probability that the last passenger sits on his own seat is still 1/2.![[n]](https://s0.wp.com/latex.php?latex=%5Bn%5D&bg=fff&fg=444444&s=0&c=20201002) ending with 1 (because at some time points, some passenger will pick seat 1, either by chance, or because seat 1 is the only seat left). Formally, let us denote a cycle of length
ending with 1 (because at some time points, some passenger will pick seat 1, either by chance, or because seat 1 is the only seat left). Formally, let us denote a cycle of length 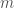 by
by  . Then the process of seating is similar to filling up a random cycle: suppose the first passenger chooses the seat
. Then the process of seating is similar to filling up a random cycle: suppose the first passenger chooses the seat 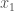 , then it corresponds to a (partially filled) cycle
, then it corresponds to a (partially filled) cycle  , we can ignore the passengers 2 till
, we can ignore the passengers 2 till  as their seats are not occupied, so they would seat on their own seat. The
as their seats are not occupied, so they would seat on their own seat. The  passenger’s seat is taken, so when he boards, he would again randomly pick a seat from
passenger’s seat is taken, so when he boards, he would again randomly pick a seat from  . Suppose he picks seat
. Suppose he picks seat  , then the cycle becomes
, then the cycle becomes  . Again nothing interesting happens until the
. Again nothing interesting happens until the  passenger boards the plane……
passenger boards the plane…… in the cycle picks
in the cycle picks (the last) seat. In this case, the cycle would end up with the
(the last) seat. In this case, the cycle would end up with the  passenger chooses the
passenger chooses the 
{kind=link}
{kind=link}