The Task Scheduling problem is from Hackerrank.
Task Scheduling
Given a list of  tasks
tasks  , where the
, where the  task has deadline
task has deadline  and duration
and duration  , for each
, for each 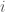 ,
,  , compute the minimum maximum lateness of the first tasks.
, compute the minimum maximum lateness of the first tasks.
First we introduce some notations which will be used in the following discussion. Given a set tasks, a schedule of the tasks is a sequence  , where each
, where each  is in
is in ![[n]](https://s0.wp.com/latex.php?latex=%5Bn%5D&bg=fff&fg=444444&s=0&c=20201002) . In other words, the sequence,
. In other words, the sequence,  is a permutation of . For example, a schedule for
is a permutation of . For example, a schedule for  , could be
, could be  (we first process task
(we first process task  , then
, then  , lastly,
, lastly, 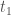 ). For a schedule
). For a schedule  , the start time for
, the start time for 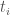 ,
,  , is
, is  (the summation of durations of all the tasks before task in the schedule), and the finish time
(the summation of durations of all the tasks before task in the schedule), and the finish time  is
is  (the start time for plus the time needed to process ). The lateness of ,
(the start time for plus the time needed to process ). The lateness of ,  for in this schedule is the difference between its finish time and its deadline,
for in this schedule is the difference between its finish time and its deadline,  . Here is an example (the input is from Hackerrank). Suppose we have 5 tasks,
. Here is an example (the input is from Hackerrank). Suppose we have 5 tasks,  . The first task has a deadline at 2, and we need 2 time units to process ; similarly, the second task has a deadline at 1, and its duration is 1, and so on. A valid schedule for these 5 tasks might be,
. The first task has a deadline at 2, and we need 2 time units to process ; similarly, the second task has a deadline at 1, and its duration is 1, and so on. A valid schedule for these 5 tasks might be,  . The start time
. The start time  , for is 0, and the finish time
, for is 0, and the finish time 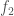 is 1, the lateness
is 1, the lateness  is
is  ; the start time
; the start time  for task is 1 (which is the finish time of the task just precedes it), and the finish time
for task is 1 (which is the finish time of the task just precedes it), and the finish time 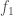 is
is  , so it has lateness
, so it has lateness  . Similarly, we can compute the start time/finish time/lateness for the rest of the tasks:
. Similarly, we can compute the start time/finish time/lateness for the rest of the tasks:  ,
,  ,
,  ;
;  ,
,  ,
,  ;
;  ,
,  ,
,  . So the maximum lateness,
. So the maximum lateness,  is 3, which is the lateness of .
is 3, which is the lateness of .
A Greedy Algorithm to Process a Set of Tasks
If we are given tasks, and our goal is to find an optimum schedule for the tasks, we can solve this problem using the greedy algorithm: sort the tasks by deadlines in non-decreasing order, and that order is the schedule minimizing the lateness. The time complexity is  .
.
The algorithm, which we will refer to  , is the following:
, is the following:

Input: a set of tasks, each task is specified by 
Output: a schedule  , where
, where ![i_j \in [n]](https://s0.wp.com/latex.php?latex=i_j+%5Cin+%5Bn%5D&bg=fff&fg=444444&s=0&c=20201002) , and the maximum lateness
, and the maximum lateness  .
.
1. Sort the tasks by the deadlines, and renumbering these tasks. Let  be the new sequence of tasks.
be the new sequence of tasks.
2. 
3. 
4. for each in

if ( )
)

5. Output  and
and
The time complexity of the above algorithm is , as the first step, sorting, takes . The rest takes 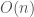 .
.
An Incremental Algorithm to Process sets of tasks
Let us now consider the Task Scheduling problem from Hackerrank. Here we need to compute the maximum lateness for sets of tasks, that is, the first tasks, for each  . For notational convenience, in the following, we use
. For notational convenience, in the following, we use  to denote the first tasks. Note that
to denote the first tasks. Note that  . The possible solutions might be:
. The possible solutions might be:
- The most naive method. Repeat for each , for . The time complexity is
 , which is
, which is  .
.
- The relatively less naive method. Note that we don’t need to repeatedly do the sorting step: once we have the optimum schedule for , we can use binary search to find the position to insert
 , which takes
, which takes  . But we still have to update the lateness. How can we do this? Since all the tasks after the newly inserted task is delayed further by
. But we still have to update the lateness. How can we do this? Since all the tasks after the newly inserted task is delayed further by  time units, their lateness might increase. So if we scan all
time units, their lateness might increase. So if we scan all 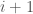 tasks to find the new maximum lateness, this would take
tasks to find the new maximum lateness, this would take  time. So the overall time complexity is
time. So the overall time complexity is  , which is
, which is  , which is
, which is  .
.
In the following, we describe an algorithm that takes time and space. Note that the main difficulty is to update the lateness, which in turn involves two subproblems: (1) compute the lateness of the newly inserted task  , so that we can compute its latesness
, so that we can compute its latesness  , and (2) compute the maximum lateness of all the tasks that are pushed time units further to the right along the time line, because of the insertion of .
, and (2) compute the maximum lateness of all the tasks that are pushed time units further to the right along the time line, because of the insertion of .
Let us first consider the first subproblem, which can be solved in logarithmic time in many ways. The easiest method to think of, is probably to use a balanced binary search tree (but note that we will use a better approach — a simpler one, although with the same time complexity). Given a list of tasks, we can build a vanilla balanced binary search tree  of the tasks, where the key is the deadline (this would allow us to find the correct position for the new task in
of the tasks, where the key is the deadline (this would allow us to find the correct position for the new task in  time, as the tree height of a balanced binary search tree with leaves is
time, as the tree height of a balanced binary search tree with leaves is  ). We can augment in the following way: store in each node not only and , but also the summation of the durations of all its descendents. This is the time that is needed to process all tasks in the subtree rooted at this node. So each node
). We can augment in the following way: store in each node not only and , but also the summation of the durations of all its descendents. This is the time that is needed to process all tasks in the subtree rooted at this node. So each node  in has three values,
in has three values,  ,
,  and
and  . When we insert a new task into , we can update this field of all ancestors of and compute the finish time of by the time we reach the bottom of simultaneously: initialize
. When we insert a new task into , we can update this field of all ancestors of and compute the finish time of by the time we reach the bottom of simultaneously: initialize 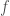 with 0. We will accumulate the time needed to process all tasks before in . Start from the root of , for each node we touched, add to
with 0. We will accumulate the time needed to process all tasks before in . Start from the root of , for each node we touched, add to  . If the deadline of the new task,
. If the deadline of the new task,  is greater than or equal to , descend to the right, and add the
is greater than or equal to , descend to the right, and add the  of the left child of and to , as the tasks in the left subtree of , and itself, are processed before in the schedule; otherwise, is less than , in this case we descend to the left child, and do not add any value to . When we reached the bottom of , we insert a new node
of the left child of and to , as the tasks in the left subtree of , and itself, are processed before in the schedule; otherwise, is less than , in this case we descend to the left child, and do not add any value to . When we reached the bottom of , we insert a new node  , for ,
, for ,  ,
,  , and
, and  (as has no descendent other than itself). is now the partial sum
(as has no descendent other than itself). is now the partial sum  , where the summation is over all the predecessors of , in other words, all the tasks processed before in the current schedule. With the finish time for , we can compute the lateness of in the current schedule as
, where the summation is over all the predecessors of , in other words, all the tasks processed before in the current schedule. With the finish time for , we can compute the lateness of in the current schedule as  . The time complexity is linear in the height of , as we only spend
. The time complexity is linear in the height of , as we only spend  time per node as we walk down the tree. Since is balanced, the time complexity is thus .
time per node as we walk down the tree. Since is balanced, the time complexity is thus .
Let us now consider the second subproblem. How can we compute the maximum lateness of current schedule? Suppose the maximum lateness occurs after , then we can easily get the new maximum lateness: consider any task in . If this task is before in the new schedule, then the insertion of has no effect on its lateness. The insertion of causes a shift for all the tasks in preceded by by time units. Therefore, their maximum lateness,  , is now increased by . Hence, the new maximum lateness is
, is now increased by . Hence, the new maximum lateness is  . What about the case where the maximum lateness occurs before ? Because the lateness of all the tasks preceded by has increased, it is possible that one of them assumes the maximum lateness. In the worst case, if is inserted to the very front of the schedule, there would be tasks after , even if we do not have to recompute the lateness of each of them, it is quite inefficient to get the maximum lateness by scanning each of them.
. What about the case where the maximum lateness occurs before ? Because the lateness of all the tasks preceded by has increased, it is possible that one of them assumes the maximum lateness. In the worst case, if is inserted to the very front of the schedule, there would be tasks after , even if we do not have to recompute the lateness of each of them, it is quite inefficient to get the maximum lateness by scanning each of them.
There are two optimizations we could make here. The first one is an observation of the lateness, the other is the use of Fenwick Tree. Let us first consider the following question: in a schedule of 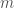 tasks,
tasks,  , ordered by their deadlines, which of these tasks might assume the maximum lateness after an insertion of a new task? Suppose we have a sequence of lateness
, ordered by their deadlines, which of these tasks might assume the maximum lateness after an insertion of a new task? Suppose we have a sequence of lateness  , where is the lateness of task in the schedule. We make the following claim:
, where is the lateness of task in the schedule. We make the following claim:
Claim: Consider a pair of tasks and  , where
, where 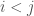 (that is, task is precedes task in the schedule). If
(that is, task is precedes task in the schedule). If  , then task can never have a larger lateness that task .
, then task can never have a larger lateness that task .
Proof: The reason is that (1) if the new task is inserted after , both and are not affected; their lateness is the same after the insertion; (2) if the new task is inserted after and before , the lateness of , remains the same, while  increased; (3) if the new task is inserted before , then both and is shifted further to the right, by an amount of — the duration of the new task, hence if is no smaller than , it will remain so after the insertion.
increased; (3) if the new task is inserted before , then both and is shifted further to the right, by an amount of — the duration of the new task, hence if is no smaller than , it will remain so after the insertion.
This observation allows us to store a sub-sequence of the lateness sequence  , which is
, which is  , where
, where  and
and  is a sub-sequence of
is a sub-sequence of  . Let us denote this list of lateness as
. Let us denote this list of lateness as  . Now we can compute the maximum lateness after the insertion of the new task: find the position where the lateness of would occur in . Suppose and
. Now we can compute the maximum lateness after the insertion of the new task: find the position where the lateness of would occur in . Suppose and  are the two indices. The maximum lateness is the maximum of the lateness before
are the two indices. The maximum lateness is the maximum of the lateness before  (as all tasks before and including precedes task , so their lateness remain the same after the insertion), the lateness of , and the maximum lateness of all the tasks after and including
(as all tasks before and including precedes task , so their lateness remain the same after the insertion), the lateness of , and the maximum lateness of all the tasks after and including  plus , which is the duration of the new task. Since the elements in is in strictly decreasing order, we can easily the get the maximums of the two parts in : the very first element of each part. Therefore, determining the maximum lateness is . However, we need to update the list : namely, we need to add a value of to each entry after and including
plus , which is the duration of the new task. Since the elements in is in strictly decreasing order, we can easily the get the maximums of the two parts in : the very first element of each part. Therefore, determining the maximum lateness is . However, we need to update the list : namely, we need to add a value of to each entry after and including  , and possibly inserting (the lateness of the new task) before
, and possibly inserting (the lateness of the new task) before  , and remove all the elements in the left part of in order to maintain the strictly increasing order in . (By the way, even if we don’t optimize further, and just naively update , the program already can pass all the tests on Hackerrank).
, and remove all the elements in the left part of in order to maintain the strictly increasing order in . (By the way, even if we don’t optimize further, and just naively update , the program already can pass all the tests on Hackerrank).
In the worst case, the size of still could be in the order of the number of all the tasks. So the overall time complexity to update could be large (for example, if is inserted before all the tasks in and each task in the optimum schedule of happens to have a decreasing lateness). While practically fast enough, the time complexity is still not yet. To avoid many updates in after an insertion, we use a simple trick: instead of explicitly storing the lateness in the list, we store the deadline. That is, if appears in , in the same position, we would store , which is the deadline of task . The deadline would serve as an id for each task. Using the deadline, we can find the finish time for the task with deadline and hence compute its lateness in the current schedule in time .
Now in an insertion, there might be several queries on the balanced binary search tree for the finish times, namely, in the set of tasks precedes in the schedule, which also appears in , we have to find those tasks whose lateness are smaller than the current maximum lateness and throw them out from . This can be done by scanning the elements in reversely from the point where is inserted, till we find a task that precedes with a larger lateness, or the list is exhausted. Since each task can only be thrown away once (if it is evicted from , it would never appear in ), therefore, the overall costs of all insertions is  .
.
After Thoughts/Alternatives
Instead of using balanced binary search tree, we could also use Fenwick Tree. Fenwick tree allows one to update an array and query partial sums on the array efficiently: each operation takes time. In some sense, it is equivalent to balanced binary search tree. But it is much easier to implement . Although conceptually not too hard, it still takes much more lines to code an augmented balanced binary search tree than Fenwick Tree. There is a balanced binary search tree in STL, but currently I don’t know any good to augment it easily. In contrast, Fenwick tree can be easily coded using array or hash table (unordered_set in STL). Of course, we could also use a regular augmented binary search tree, without the rotation operations to keep the tree balanced, and rely on the fact that if the keys of the input for constructing the binary search tree is random, then the tree height has expectation .






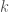

![P[1..i]](https://s0.wp.com/latex.php?latex=P%5B1..i%5D&bg=fff&fg=444444&s=0&c=20201002)


![{\rm BestFit}(i+1) = \max_{1 \leq j \leq i+1}\{{\rm BestFit}(j-1) + {\rm fit}(P[j..i+1])\}](https://s0.wp.com/latex.php?latex=%7B%5Crm+BestFit%7D%28i%2B1%29+%3D+%5Cmax_%7B1+%5Cleq+j+%5Cleq+i%2B1%7D%5C%7B%7B%5Crm+BestFit%7D%28j-1%29+%2B+%7B%5Crm+fit%7D%28P%5Bj..i%2B1%5D%29%5C%7D&bg=fff&fg=444444&s=0&c=20201002)





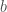







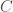


![{\rm BestFit}(i+1) = \min_{1 \leq j \leq i+1}({\rm fit}(P[j..i+1]) + C + {\rm BestFit}(i))](https://s0.wp.com/latex.php?latex=%7B%5Crm+BestFit%7D%28i%2B1%29+%3D+%5Cmin_%7B1+%5Cleq+j+%5Cleq+i%2B1%7D%28%7B%5Crm+fit%7D%28P%5Bj..i%2B1%5D%29+%2B+C+%2B+%7B%5Crm+BestFit%7D%28i%29%29&bg=fff&fg=444444&s=0&c=20201002)

![{\rm fit}(P[j..i+1])](https://s0.wp.com/latex.php?latex=%7B%5Crm+fit%7D%28P%5Bj..i%2B1%5D%29&bg=fff&fg=444444&s=0&c=20201002)
![P[j..i+1]](https://s0.wp.com/latex.php?latex=P%5Bj..i%2B1%5D&bg=fff&fg=444444&s=0&c=20201002)
![{\rm fit}(P[i..j])](https://s0.wp.com/latex.php?latex=%7B%5Crm+fit%7D%28P%5Bi..j%5D%29&bg=fff&fg=444444&s=0&c=20201002)
 and
and 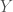 is formed by interspersing the characters into a new string, keeping the characters of
is formed by interspersing the characters into a new string, keeping the characters of ![S_1[1..m]](https://s0.wp.com/latex.php?latex=S_1%5B1..m%5D&bg=fff&fg=444444&s=0&c=20201002) ,
, ![S_2[1..n]](https://s0.wp.com/latex.php?latex=S_2%5B1..n%5D&bg=fff&fg=444444&s=0&c=20201002) and
and ![S[1..n+m]](https://s0.wp.com/latex.php?latex=S%5B1..n%2Bm%5D&bg=fff&fg=444444&s=0&c=20201002) , describe and analyze an algorithm to determine whether
, describe and analyze an algorithm to determine whether  and
and  to be true if
to be true if ![S[1..i+j]](https://s0.wp.com/latex.php?latex=S%5B1..i%2Bj%5D&bg=fff&fg=444444&s=0&c=20201002) is a shuffle of
is a shuffle of ![S_1[1..i]](https://s0.wp.com/latex.php?latex=S_1%5B1..i%5D&bg=fff&fg=444444&s=0&c=20201002) and
and ![S_2[i..j]](https://s0.wp.com/latex.php?latex=S_2%5Bi..j%5D&bg=fff&fg=444444&s=0&c=20201002) , and false otherwise, for
, and false otherwise, for  and
and  .
.  . (An empty string is a shuffle of two empty strings).
. (An empty string is a shuffle of two empty strings). , then
, then  is true if and only if the string
is true if and only if the string  .
. , then
, then  is true if and only if the string
is true if and only if the string ![S_2[1..j]](https://s0.wp.com/latex.php?latex=S_2%5B1..j%5D&bg=fff&fg=444444&s=0&c=20201002) is a prefix of the string
is a prefix of the string 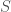 , for
, for  .
.![S_1[i] \neq S_2[j]](https://s0.wp.com/latex.php?latex=S_1%5Bi%5D+%5Cneq+S_2%5Bj%5D&bg=fff&fg=444444&s=0&c=20201002) , then
, then  equals to
equals to  if
if ![S[i+j] = S_1[i]](https://s0.wp.com/latex.php?latex=S%5Bi%2Bj%5D+%3D+S_1%5Bi%5D&bg=fff&fg=444444&s=0&c=20201002) , and
, and  if
if ![S[i+j] = S_2[j]](https://s0.wp.com/latex.php?latex=S%5Bi%2Bj%5D+%3D+S_2%5Bj%5D&bg=fff&fg=444444&s=0&c=20201002) ; otherwise it is false.
; otherwise it is false.![S_1[i] = S_2[j]](https://s0.wp.com/latex.php?latex=S_1%5Bi%5D+%3D+S_2%5Bj%5D&bg=fff&fg=444444&s=0&c=20201002) , then
, then  .
.
 is the final answer.
is the final answer.  , the space complexity is
, the space complexity is  .
.  .
.
 ) algorithm for this problem?
) algorithm for this problem?  , for
, for  , and similarly, for the second random generator, the probability that the randomly generated number
, and similarly, for the second random generator, the probability that the randomly generated number  ,
,  Define two polynomials
Define two polynomials  and
and  . Then consider the multiplication of
. Then consider the multiplication of  :
: ,
, coefficient in the right hand side of the above equation is precisely the probability of
coefficient in the right hand side of the above equation is precisely the probability of  . So the probability that
. So the probability that  is the summation of the first
is the summation of the first  terms. In the problem of interview street, since the distribution is uniform, each
terms. In the problem of interview street, since the distribution is uniform, each  , and each
, and each  . So we can easily obtain the probability that
. So we can easily obtain the probability that  .
. . Similarly, let
. Similarly, let 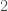 is
is  (the first dice and second dice must both output 1). The probability that the sum is 12 is
(the first dice and second dice must both output 1). The probability that the sum is 12 is  (both dices must output 6). Then consider the probability that the sum is 7: it is at least
(both dices must output 6). Then consider the probability that the sum is 7: it is at least  (the first dice outputs 1, and the second dice outputs 6, or the reverse). But
(the first dice outputs 1, and the second dice outputs 6, or the reverse). But  .
. and let
and let  . Now if the sums 2,3,…,12 comes with the same probability, 1/11, then we have
. Now if the sums 2,3,…,12 comes with the same probability, 1/11, then we have . Now since both
. Now since both  and
and  are polynomials of degree 5,
are polynomials of degree 5,  has real roots; however, the right hand side is a cyclotomic polynomial which does not have any real root. Thus the identity cannot hold.
has real roots; however, the right hand side is a cyclotomic polynomial which does not have any real root. Thus the identity cannot hold.![p_1, ..., p_n \in [0,1]](https://s0.wp.com/latex.php?latex=p_1%2C+...%2C+p_n+%5Cin+%5B0%2C1%5D&bg=fff&fg=444444&s=0&c=20201002) , you want to determine the probability of obtaining exactly
, you want to determine the probability of obtaining exactly ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=fff&fg=444444&s=0&c=20201002) in
in  be the indicator random variable for the event that the result of tossing
be the indicator random variable for the event that the result of tossing  coin is head, for
coin is head, for  . Notice that
. Notice that .
.  , for
, for  . The probability of obtaining
. The probability of obtaining  . Therefore, the problem is reduced to how fast we can multiply polynomials. Using fast fourier transform, we can multiply two polynomials of degree at most
. Therefore, the problem is reduced to how fast we can multiply polynomials. Using fast fourier transform, we can multiply two polynomials of degree at most  .
.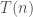 denotes the time to multiply
denotes the time to multiply  ,
, . Hence
. Hence  .
.  , and a target value
, and a target value  , and the target is 122, then the optimum way to pick the denominations is
, and the target is 122, then the optimum way to pick the denominations is  , so the number of bills we need is 5.
, so the number of bills we need is 5. 1’s). W.l.o.g., assume that
1’s). W.l.o.g., assume that  . The recursion formula is the following: define
. The recursion formula is the following: define  to be the smallest number of bills we need to get
to be the smallest number of bills we need to get  . The base cases are:
. The base cases are:  , for
, for  ;
;  for
for  . For
. For  and
and  , if
, if  , then
, then  , where
, where  is the largest index satisfying
is the largest index satisfying  ; otherwise,
; otherwise,  .
. , where
, where 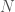 is the target value. So it is a psedu-polynomial time complexity algorithm. The space complexity is
is the target value. So it is a psedu-polynomial time complexity algorithm. The space complexity is  . In the code below, I used “recursion + memoization” approach (the reason is given
. In the code below, I used “recursion + memoization” approach (the reason is given  and
and  on
on  on
on  to the corresponding point
to the corresponding point  .
. ,
,  , where
, where  is the set of segments in
is the set of segments in  , so that they are ordered from left to right, and we also renumber the corresponding indices of
, so that they are ordered from left to right, and we also renumber the corresponding indices of  to
to  to
to  , and the space complexity is
, and the space complexity is  .
. . If the array is not filled up, add new element into the array. If the array is filled up, use the median selection algorithm to find the median of current
. If the array is not filled up, add new element into the array. If the array is filled up, use the median selection algorithm to find the median of current  element, and discard the
element, and discard the 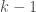 elements which are greater than the median. This takes
elements which are greater than the median. This takes  times, so the time complexity is
times, so the time complexity is  .
.![s[1..n]](https://s0.wp.com/latex.php?latex=s%5B1..n%5D&bg=fff&fg=444444&s=0&c=20201002) , which you believe to be a corrupted text document in which all punctuation has vanished (so that it looks something like “itwasthebestoftime…”). You wish to reconstruct the document using a dictionary, which is available in the form of an Boolean function
, which you believe to be a corrupted text document in which all punctuation has vanished (so that it looks something like “itwasthebestoftime…”). You wish to reconstruct the document using a dictionary, which is available in the form of an Boolean function  : for any string
: for any string 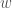 ,
,  returns true if
returns true if ![s[\cdot]](https://s0.wp.com/latex.php?latex=s%5B%5Ccdot%5D&bg=fff&fg=444444&s=0&c=20201002) can be reconstituted as a sequence of valid words. The running time should be at most
can be reconstituted as a sequence of valid words. The running time should be at most  to be a function over strings, where
to be a function over strings, where  (the empty string is considered as a valid word in dictionary, and thus a valid sentence vacuously); for
(the empty string is considered as a valid word in dictionary, and thus a valid sentence vacuously); for  ,
, .
. can only be broken into valid words if and only if there exists some index
can only be broken into valid words if and only if there exists some index  , such that the string
, such that the string  is a word in the dictionary, and the remaining string can be broken into a sequence of valid words). We can slightly simplify the notation by dropping the end index of the string:
is a word in the dictionary, and the remaining string can be broken into a sequence of valid words). We can slightly simplify the notation by dropping the end index of the string:
 for
for  .
.
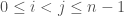 to see if the sum of the subarray
to see if the sum of the subarray ![A[i..j]](https://s0.wp.com/latex.php?latex=A%5Bi..j%5D&bg=fff&fg=444444&s=0&c=20201002) is no greater than
is no greater than 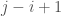 . To avoid repeatedly computing the subarray sum, one can first preprocess the array to get an array
. To avoid repeatedly computing the subarray sum, one can first preprocess the array to get an array ![S[i] = \sum_{j = 0}^{i-1} A[j]](https://s0.wp.com/latex.php?latex=S%5Bi%5D+%3D+%5Csum_%7Bj+%3D+0%7D%5E%7Bi-1%7D+A%5Bj%5D&bg=fff&fg=444444&s=0&c=20201002) , for
, for ![S[0] = 0](https://s0.wp.com/latex.php?latex=S%5B0%5D+%3D+0&bg=fff&fg=444444&s=0&c=20201002) . Then the subarray sum can be obtained as
. Then the subarray sum can be obtained as ![A[i..j] = S[j+1] - S[i]](https://s0.wp.com/latex.php?latex=A%5Bi..j%5D+%3D+S%5Bj%2B1%5D+-+S%5Bi%5D&bg=fff&fg=444444&s=0&c=20201002) . The preprocessing takes linear time and linear space.
. The preprocessing takes linear time and linear space.![A[0..n-1]](https://s0.wp.com/latex.php?latex=A%5B0..n-1%5D&bg=fff&fg=444444&s=0&c=20201002) ,
, 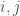 , maximizing
, maximizing 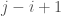 , subject to
, subject to ![\sum_{t = i}^j A[t] \leq k](https://s0.wp.com/latex.php?latex=%5Csum_%7Bt+%3D+i%7D%5Ej+A%5Bt%5D+%5Cleq+k&bg=fff&fg=444444&s=0&c=20201002)
![S[0..n]](https://s0.wp.com/latex.php?latex=S%5B0..n%5D&bg=fff&fg=444444&s=0&c=20201002) of partial sums, where
of partial sums, where ![S[i]](https://s0.wp.com/latex.php?latex=S%5Bi%5D&bg=fff&fg=444444&s=0&c=20201002) is the prefix sum of the first
is the prefix sum of the first ![S[0] \leftarrow 0](https://s0.wp.com/latex.php?latex=S%5B0%5D+%5Cleftarrow+0&bg=fff&fg=444444&s=0&c=20201002) .
.
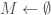

 down to 0
down to 0![S[i] < {\rm smallest}](https://s0.wp.com/latex.php?latex=S%5Bi%5D+%3C+%7B%5Crm+smallest%7D&bg=fff&fg=444444&s=0&c=20201002)
![M \leftarrow M \cup \{(S[i], i)\}](https://s0.wp.com/latex.php?latex=M+%5Cleftarrow+M+%5Ccup+%5C%7B%28S%5Bi%5D%2C+i%29%5C%7D&bg=fff&fg=444444&s=0&c=20201002)
![{\rm smallest} \leftarrow S[i]](https://s0.wp.com/latex.php?latex=%7B%5Crm+smallest%7D+%5Cleftarrow+S%5Bi%5D&bg=fff&fg=444444&s=0&c=20201002)
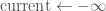
 up to
up to 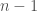
![S[i] > {\rm current}](https://s0.wp.com/latex.php?latex=S%5Bi%5D+%3E+%7B%5Crm+current%7D&bg=fff&fg=444444&s=0&c=20201002)
![(S[t], t)](https://s0.wp.com/latex.php?latex=%28S%5Bt%5D%2C+t%29&bg=fff&fg=444444&s=0&c=20201002) in
in  such that
such that ![S[t] - S[i] \leq k](https://s0.wp.com/latex.php?latex=S%5Bt%5D+-+S%5Bi%5D+%5Cleq+k&bg=fff&fg=444444&s=0&c=20201002) . If such an element exists, update
. If such an element exists, update  to
to 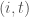 if
if 
![{\rm current} \leftarrow S[i]](https://s0.wp.com/latex.php?latex=%7B%5Crm+current%7D+%5Cleftarrow+S%5Bi%5D&bg=fff&fg=444444&s=0&c=20201002)
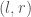
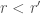 satisfies that
satisfies that ![S[r] \geq S[r']](https://s0.wp.com/latex.php?latex=S%5Br%5D+%5Cgeq+S%5Br%27%5D&bg=fff&fg=444444&s=0&c=20201002) , then
, then  cannot appear in an optimum solution; (2) If two indices
cannot appear in an optimum solution; (2) If two indices  satisfies that
satisfies that ![S[l] \geq S[l']](https://s0.wp.com/latex.php?latex=S%5Bl%5D+%5Cgeq+S%5Bl%27%5D&bg=fff&fg=444444&s=0&c=20201002) , then
, then  cannot appear in an optimum solution.
cannot appear in an optimum solution.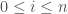 , note that the subarray sum of
, note that the subarray sum of ![A[i..r']](https://s0.wp.com/latex.php?latex=A%5Bi..r%27%5D&bg=fff&fg=444444&s=0&c=20201002) is less than the subarray sum of
is less than the subarray sum of ![A[i..r]](https://s0.wp.com/latex.php?latex=A%5Bi..r%5D&bg=fff&fg=444444&s=0&c=20201002) , and the length of the subarray $A[i..r’]$ is greater than the length of the subarray
, and the length of the subarray $A[i..r’]$ is greater than the length of the subarray 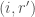 is preferable over
is preferable over  . This is also the reason why we compute the strictly increasing sequence of
. This is also the reason why we compute the strictly increasing sequence of 