Given a sequence of distinct numbers  , the sequence is a zig-zag sequence if either (1)
, the sequence is a zig-zag sequence if either (1)  , that is, an empty sequence or a sequence with a single element are both the trivial zig-zag sequence; or (2) otherwise, the sign of the difference between adjacent element alternates.
, that is, an empty sequence or a sequence with a single element are both the trivial zig-zag sequence; or (2) otherwise, the sign of the difference between adjacent element alternates.
For example, the sequence 2,3,1 is a zig-zag sequence because 2 < 3 and 3 > 1 while 1,2,3 is not. The questions are
(1) given a sequence of numbers, compute a zigzag sequence of these numbers;
(2) given  , count the number of zigzag sequences of
, count the number of zigzag sequences of ![[n]](https://s0.wp.com/latex.php?latex=%5Bn%5D&bg=fff&fg=444444&s=0&c=20201002) ( denotes the set of elements
( denotes the set of elements  ).
).
The first question is easy and it has a linear time algorithm: if the input has only 1 element, we are done. So suppose the input has at least two elements. Scan the sequence from left to right, for two adjacent element  and
and  ,
,  , if they satisfy the inequality (which is “>” for
, if they satisfy the inequality (which is “>” for 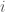 even and “<” for odd), then increment ; otherwise, swap and . Then increment . We repeat this until we reach
even and “<” for odd), then increment ; otherwise, swap and . Then increment . We repeat this until we reach  ..
..
As an example, consider the input 4, 1, 2, 3, 5: the target is to get a sequence  . Let’s number the elements, so
. Let’s number the elements, so  ,
,  , and so on.
, and so on.
The starting sequence is  .
.
 :
:
Since 4 > 1, we swap 4 and 1, the new sequence is 1, 4, 2, 3, 5;
 :
:
Since 4 > 2, it satisfies that  .
.
 :
:
Since 2 < 3, it satisfies that  .
.
 :
:
Since 3 < 5, we swap 5 and 3, to get 1, 4, 2, 5, 3.
The output is hence 1, 4, 2, 5, 3.
The recursive algorithm does not differ too much from the above imperative one.
A sequence ![A[1..n]](https://s0.wp.com/latex.php?latex=A%5B1..n%5D&bg=fff&fg=444444&s=0&c=20201002) is a “happy zigzag” sequence if either (1) , in which case it is a trivial happy zigzag sequence; or (2)
is a “happy zigzag” sequence if either (1) , in which case it is a trivial happy zigzag sequence; or (2)  ,
, ![A[1] < A[2]](https://s0.wp.com/latex.php?latex=A%5B1%5D+%3C+A%5B2%5D&bg=fff&fg=444444&s=0&c=20201002) , and
, and ![A[2..n]](https://s0.wp.com/latex.php?latex=A%5B2..n%5D&bg=fff&fg=444444&s=0&c=20201002) is a sag zigzag sequence.
is a sag zigzag sequence.
A sequence is a “sad zigzag” sequence if either (1) , in which case it is a trivial sad zigzag sequence; or (2) , ![A[1] > A[2]](https://s0.wp.com/latex.php?latex=A%5B1%5D+%3E+A%5B2%5D&bg=fff&fg=444444&s=0&c=20201002) , and is a happy zigzag sequence.
, and is a happy zigzag sequence.
To compute a happy zigzag sequence, if the first two elements of satisfies ![A[1]<A[2]](https://s0.wp.com/latex.php?latex=A%5B1%5D%3CA%5B2%5D&bg=fff&fg=444444&s=0&c=20201002) , then we compute a sad zigzag sequence of , and the output is
, then we compute a sad zigzag sequence of , and the output is ![A[1]](https://s0.wp.com/latex.php?latex=A%5B1%5D&bg=fff&fg=444444&s=0&c=20201002) concatenated with this sequence; otherwise, we swap and
concatenated with this sequence; otherwise, we swap and ![A[2]](https://s0.wp.com/latex.php?latex=A%5B2%5D&bg=fff&fg=444444&s=0&c=20201002) , then proceed as the previous case.
, then proceed as the previous case.
getSnake :: (Ord a) => [a] -> (a->a->Bool, a->a->Bool) -> [a]
getSnake [] _ = []
getSnake [x] _ = [x]
getSnake (x:y:xs) (f,g)
|f x y = x : (getSnake (y:xs) (g,f))
|otherwise = y : (getSnake (x:xs) (g,f))
getSnake' :: (Ord a) => [a] -> [a]
getSnake' x = getSnake x ((<), (>))
The second problem is much harder than the first one. The number of zig-zag sequences for  to 7 are 1,2,5,16,61,272,1385. Look familiar? Here is the surprising connection from [1]:
to 7 are 1,2,5,16,61,272,1385. Look familiar? Here is the surprising connection from [1]:

 .
.
An interesting object is the following zigzag triangle from [1]:
1
0 1
1 1 0
0 1 2 2
5 5 4 2 0
0 5 10 14 16 16
61 61 56 46 32 16 0
The triangle is filled in the following way: the first row is 1. The  row is computed from the
row is computed from the  row: we alternate the direction of filling up the row, and the starting element is 0. We fill up the row using the zig-zag rule:
row: we alternate the direction of filling up the row, and the starting element is 0. We fill up the row using the zig-zag rule:
a
b -> (a+b)
The key observation is that the element in  row is the number of zigzag sequence ending with : for example, for
row is the number of zigzag sequence ending with : for example, for  , the zigzag sequences are the following (sorted by ending element):
, the zigzag sequences are the following (sorted by ending element):
[[3,4,2,5,1],[2,5,3,4,1],[3,5,2,4,1],[2,4,3,5,1],[4,5,2,3,1],[1,4,3,5,2],[4,5,1,3,2],[1,5,3,4,2],[3,5,1,4,2],[3,4,1,5,2],[1,4,2,5,3],[1,5,2,4,3],[2,5,1,4,3],[2,4,1,5,3],[2,3,1,5,4],[1,3,2,5,4]]
The fifth row in the zigzag triangle is 5, 5, 4, 2, 0. This connection also gives an efficient recursive algorithm to count the number of zigzag sequences.
Update:
(1) The zigzag sequence is essentially alternating permutation.
(2) The recursive algorithm (getSnake) above can also be used to find a longest alternating permutation in quadratic time.
Reference
[1] Some Very Interesting Sequences, John H. Conway and Tim Hsu. (link)
 is uniformly distributed over
is uniformly distributed over ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=fff&fg=444444&s=0&c=20201002) if for each interval
if for each interval ![[a,b) \subset [0,1]](https://s0.wp.com/latex.php?latex=%5Ba%2Cb%29+%5Csubset+%5B0%2C1%5D&bg=fff&fg=444444&s=0&c=20201002) ,
, . How does a uniformly distributed sequence over the unit interval look like?
. How does a uniformly distributed sequence over the unit interval look like? is
is  .
.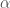 , the sequence
, the sequence  is the fractional part of
is the fractional part of  , denoted by
, denoted by  (
( is the fractional part of
is the fractional part of  ), is uniformly distributed over
), is uniformly distributed over  .
.
 , where
, where  , we have
, we have : The nice thing is that
: The nice thing is that  equals to
equals to  — the fractional operator
— the fractional operator  disappears because
disappears because  is 1 for any integer
is 1 for any integer 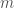 . Therefore, we can compute
. Therefore, we can compute  easily, it is simply
easily, it is simply  , which is nothing but a geometric sum
, which is nothing but a geometric sum  , which is
, which is  . Since
. Since  is never 1, hence the denominator is nonzero. The magnitude of
is never 1, hence the denominator is nonzero. The magnitude of  , as the magnitude of
, as the magnitude of  .
. , we have
, we have . In particular, this implies that for all trigonometric polynomials
. In particular, this implies that for all trigonometric polynomials  , where
, where  are real numbers, it holds that
are real numbers, it holds that . Using Weierstrass’ approximation theorem, one can show that the equation holds for all functions
. Using Weierstrass’ approximation theorem, one can show that the equation holds for all functions  , where
, where  for
for  and 0 otherwise,
and 0 otherwise, ![a, b \in [0,1]](https://s0.wp.com/latex.php?latex=a%2C+b+%5Cin+%5B0%2C1%5D&bg=fff&fg=444444&s=0&c=20201002) –this is precisely the requirement for
–this is precisely the requirement for  being uniformly distributed over
being uniformly distributed over 



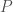 of
of ![[0,1]^2](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D%5E2&bg=fff&fg=444444&s=0&c=20201002) , define the
, define the  discrepancy for corners of
discrepancy for corners of ![D_2(P, \mathcal{C}) = \sqrt{\int_{[0,1]^2}(D(P, C_x))^2dx}](https://s0.wp.com/latex.php?latex=D_2%28P%2C+%5Cmathcal%7BC%7D%29+%3D+%5Csqrt%7B%5Cint_%7B%5B0%2C1%5D%5E2%7D%28D%28P%2C+C_x%29%29%5E2dx%7D&bg=fff&fg=444444&s=0&c=20201002) ,
, is the corner rectangle
is the corner rectangle  for the point
for the point ![x = (x_1,x_2) \in [0,1]^2](https://s0.wp.com/latex.php?latex=x+%3D+%28x_1%2Cx_2%29+%5Cin+%5B0%2C1%5D%5E2&bg=fff&fg=444444&s=0&c=20201002) , and
, and  is a function of
is a function of  (the discrepancy of
(the discrepancy of  is the set of all corner rectangles
is the set of all corner rectangles ![\{C_x \vert x \in [0,1]^2\}](https://s0.wp.com/latex.php?latex=%5C%7BC_x+%5Cvert+x+%5Cin+%5B0%2C1%5D%5E2%5C%7D&bg=fff&fg=444444&s=0&c=20201002) .
.![x \in [0,1]^2](https://s0.wp.com/latex.php?latex=x+%5Cin+%5B0%2C1%5D%5E2&bg=fff&fg=444444&s=0&c=20201002) , the expectation of the number of points falling in
, the expectation of the number of points falling in  , is
, is  . So the quantity
. So the quantity  , which is the difference the the latter and the former, measures the deviation of
, which is the difference the the latter and the former, measures the deviation of  is small. For example, one candidate might be the grid
is small. For example, one candidate might be the grid  in the unit square (Although this seems to be a good way to put
in the unit square (Although this seems to be a good way to put  for some function
for some function 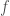 depending on
depending on  of
of  is from “Geometric Discrepancy” by Matousek. The proof is quite short, but is indeed ingenious (it is that kind of proof that gives the feeling of “opening a magical door”).
is from “Geometric Discrepancy” by Matousek. The proof is quite short, but is indeed ingenious (it is that kind of proof that gives the feeling of “opening a magical door”). from now on (as we fix
from now on (as we fix  ,
,  , is a piece-wise continuous function over the unit square. The second term,
, is a piece-wise continuous function over the unit square. The second term,  . Indeed, it can be computed in
. Indeed, it can be computed in  time. However, the difficulty is that we need to take the lower bound
time. However, the difficulty is that we need to take the lower bound ![\inf_{P \subset [0,1]^2, \vert P \vert = n} D_2(P,\mathcal{C})](https://s0.wp.com/latex.php?latex=%5Cinf_%7BP+%5Csubset+%5B0%2C1%5D%5E2%2C+%5Cvert+P+%5Cvert+%3D+n%7D+D_2%28P%2C%5Cmathcal%7BC%7D%29&bg=fff&fg=444444&s=0&c=20201002) . It is even quite unclear how the discrepancy changes as we vary
. It is even quite unclear how the discrepancy changes as we vary  .
.![F:[0,1]^2 \to \{-1,0,1\}](https://s0.wp.com/latex.php?latex=F%3A%5B0%2C1%5D%5E2+%5Cto+%5C%7B-1%2C0%2C1%5C%7D&bg=fff&fg=444444&s=0&c=20201002) to obtain the lower bound: we have
to obtain the lower bound: we have![\int_{[0,1]^2} F(x)D(x)dx \leq \sqrt{\int_{[0,1]^2}(F(x))^2 dx} \sqrt{\int_{[0,1]^2}(D(x))^2 dx}](https://s0.wp.com/latex.php?latex=%5Cint_%7B%5B0%2C1%5D%5E2%7D+F%28x%29D%28x%29dx+%5Cleq+%5Csqrt%7B%5Cint_%7B%5B0%2C1%5D%5E2%7D%28F%28x%29%29%5E2+dx%7D+%5Csqrt%7B%5Cint_%7B%5B0%2C1%5D%5E2%7D%28D%28x%29%29%5E2+dx%7D&bg=fff&fg=444444&s=0&c=20201002) by Cauchy-Scharwz inequality. Then a lower bound of
by Cauchy-Scharwz inequality. Then a lower bound of  is
is![\sqrt{\int_{[0,1]^2} (D(x))^2 dx} \geq (\int_{[0,1]^2} F(x)D(x)dx)/(\sqrt{\int_{[0,1]^2}(F(x))^2 dx})](https://s0.wp.com/latex.php?latex=%5Csqrt%7B%5Cint_%7B%5B0%2C1%5D%5E2%7D+%28D%28x%29%29%5E2+dx%7D+%5Cgeq+%28%5Cint_%7B%5B0%2C1%5D%5E2%7D+F%28x%29D%28x%29dx%29%2F%28%5Csqrt%7B%5Cint_%7B%5B0%2C1%5D%5E2%7D%28F%28x%29%29%5E2+dx%7D%29&bg=fff&fg=444444&s=0&c=20201002) . So if we could construct a function
. So if we could construct a function  such that
such that![\int_{[0,1]^2} F(x)D(x)dx](https://s0.wp.com/latex.php?latex=%5Cint_%7B%5B0%2C1%5D%5E2%7D+F%28x%29D%28x%29dx&bg=fff&fg=444444&s=0&c=20201002) is
is  ;
;![\sqrt{\int_{[0,1]^2}(F(x))^2 dx}](https://s0.wp.com/latex.php?latex=%5Csqrt%7B%5Cint_%7B%5B0%2C1%5D%5E2%7D%28F%28x%29%29%5E2+dx%7D&bg=fff&fg=444444&s=0&c=20201002) is
is  .
. . Define
. Define ![f_j: [0,1]^2 \to \{-1,0,1\}](https://s0.wp.com/latex.php?latex=f_j%3A+%5B0%2C1%5D%5E2+%5Cto+%5C%7B-1%2C0%2C1%5C%7D&bg=fff&fg=444444&s=0&c=20201002) ,
,  , where
, where  is defined as following: partition the unit square into
is defined as following: partition the unit square into  vertical slabs, then again partition it into
vertical slabs, then again partition it into  horizontal slabs. So we get
horizontal slabs. So we get  rectangles in total. If a rectangle
rectangles in total. If a rectangle 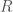 contains any point from
contains any point from  are:
are: and
and ![\int_{[0,1]^2} f_i(x)f_j(x)dx = 0](https://s0.wp.com/latex.php?latex=%5Cint_%7B%5B0%2C1%5D%5E2%7D+f_i%28x%29f_j%28x%29dx+%3D+0&bg=fff&fg=444444&s=0&c=20201002) for
for  . We set
. We set  . The orthogonality immediately implies that
. The orthogonality immediately implies that ![\int_{[0,1]^2}(F(x))^2 dx](https://s0.wp.com/latex.php?latex=%5Cint_%7B%5B0%2C1%5D%5E2%7D%28F%28x%29%29%5E2+dx&bg=fff&fg=444444&s=0&c=20201002) is at most
is at most  , which is
, which is  .
.![\int_{[0,1]^2}f_j(x)D(x)dx](https://s0.wp.com/latex.php?latex=%5Cint_%7B%5B0%2C1%5D%5E2%7Df_j%28x%29D%28x%29dx&bg=fff&fg=444444&s=0&c=20201002) is
is  . This immediately implies that
. This immediately implies that ![\int_{[0,1]^2}F(x)D(x)dx](https://s0.wp.com/latex.php?latex=%5Cint_%7B%5B0%2C1%5D%5E2%7DF%28x%29D%28x%29dx&bg=fff&fg=444444&s=0&c=20201002) is
is  , which is
, which is  ,
, 
 ,
, ,
,  .
. (resp.
(resp.  ).
). of distinct numbers
of distinct numbers  , such that the sign of the difference between adjacent elements in
, such that the sign of the difference between adjacent elements in  is a monotone run of
is a monotone run of  , is at least 2; (2) the sign of adjacent elements in this subsequence does not change; (3) the subsequence
, is at least 2; (2) the sign of adjacent elements in this subsequence does not change; (3) the subsequence  is maximal in the sense that no other monotone run of
is maximal in the sense that no other monotone run of  , then any oscillating subsequence contains at most two elements from
, then any oscillating subsequence contains at most two elements from  and
and  , and at most two elements from
, and at most two elements from  , and so on. So we can prove that the length of such a sequence is
, and so on. So we can prove that the length of such a sequence is  by induction.
by induction. . They can form two clubs:
. They can form two clubs:  and
and  . In fact, that is the largest number of clubs they can form (because the other two sets,
. In fact, that is the largest number of clubs they can form (because the other two sets,  and
and  are not valid clubs since their cardinality is even).
are not valid clubs since their cardinality is even). ,
,  is a valid set of clubs. The question is that whether 32 is the largest number of clubs they can form? The problem has a surprisingly simple and elegant solution (using linear algebra method).
is a valid set of clubs. The question is that whether 32 is the largest number of clubs they can form? The problem has a surprisingly simple and elegant solution (using linear algebra method). , where
, where  is the field
is the field  (the field of
(the field of  ): represent club
): represent club  as a vector
as a vector  , where the
, where the  entry is 1 if
entry is 1 if  , and 0 otherwise. Note that the inner product
, and 0 otherwise. Note that the inner product  ,
,  , is the number of common members between
, is the number of common members between  modulo 2. From rule (1),
modulo 2. From rule (1),  , since it is the cardinality of
, since it is the cardinality of  ,
,  , since it is an even number modulo 2. The key observation is that the set of vectors is linearly independent over
, since it is an even number modulo 2. The key observation is that the set of vectors is linearly independent over  , and thus respectively
, and thus respectively  . It suffices to show that if
. It suffices to show that if (*), where each
(*), where each  , then
, then  for all
for all  .
. .
. is 1, and each
is 1, and each  ,
,  is 0,
is 0,  therefore must be 0. Following similar approach, we conclude that
therefore must be 0. Following similar approach, we conclude that  . Hence the set
. Hence the set  as a decimal fraction, what are the digits immediately to the left and to the right of the decimal point?
as a decimal fraction, what are the digits immediately to the left and to the right of the decimal point? , the digit immediately to the left of the decimal point is 9, and the digit to the right is 8.
, the digit immediately to the left of the decimal point is 9, and the digit to the right is 8.  ,
, 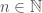 is the sum of an integer and a multiple of
is the sum of an integer and a multiple of  . For example, for
. For example, for  . This is straight forward from binomial theorem:
. This is straight forward from binomial theorem: .
.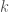 odd, a term
odd, a term  is a multiple of
is a multiple of  , for
, for  , where
, where  are integers.
are integers.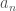 and
and  is:
is: ,
,  . Using the machinery of generating functions, we get a closed form of
. Using the machinery of generating functions, we get a closed form of  . As
. As  , we get
, we get  , which implies that
, which implies that . (*)
. (*) is the fractional part of
is the fractional part of  . From (*), what can we infer about
. From (*), what can we infer about  must sum up to an integer. The crucial observation is that
must sum up to an integer. The crucial observation is that  , therefore, when it is raised to a large power, say, 990,
, therefore, when it is raised to a large power, say, 990,  is very close to 0 — it is of the form "0.000….". This implies that
is very close to 0 — it is of the form "0.000….". This implies that  must be of the form "0.999…..". Thus, the digit immediately to the right of the decimal point in
must be of the form "0.999…..". Thus, the digit immediately to the right of the decimal point in  and the integral part of
and the integral part of  . Following a similar reasoning as the above, we see that the integral part of
. Following a similar reasoning as the above, we see that the integral part of  is completely determined by
is completely determined by  modulo 10. For
modulo 10. For  , the first 6 pairs of the last digits of
, the first 6 pairs of the last digits of  is
is  . Therefore, it is periodic with period 4. Hence,
. Therefore, it is periodic with period 4. Hence,  . Therefore, the digit immediately to the left of the decimal point of
. Therefore, the digit immediately to the left of the decimal point of  .
.