Maximum sum increasing subsequence: Given a sequence of positive numbers ![S[1..n]](https://s0.wp.com/latex.php?latex=S%5B1..n%5D&bg=fff&fg=444444&s=0&c=20201002) , find an increasing subsequence, maximizing the summation of the elements in the subsequence.
, find an increasing subsequence, maximizing the summation of the elements in the subsequence.
In other words, the goal is to find some 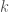 indices,
indices,  ,
,  , such that
, such that
(1) ![S[i_j] \le S[i_{j+1}]](https://s0.wp.com/latex.php?latex=S%5Bi_j%5D+%5Cle+S%5Bi_%7Bj%2B1%7D%5D&bg=fff&fg=444444&s=0&c=20201002) for
for  ,
,
(2) ![\sum_{j = 1}^k S[i_j]](https://s0.wp.com/latex.php?latex=%5Csum_%7Bj+%3D+1%7D%5Ek+S%5Bi_j%5D&bg=fff&fg=444444&s=0&c=20201002) is maximum over all increasing subsequence of .
is maximum over all increasing subsequence of .
One can use dynamic programming to achieve time complexity  : let
: let  , where
, where  , denotes the maximum sum increasing subsequence of
, denotes the maximum sum increasing subsequence of ![S[1..i]](https://s0.wp.com/latex.php?latex=S%5B1..i%5D&bg=fff&fg=444444&s=0&c=20201002) which ends at
which ends at ![S[i]](https://s0.wp.com/latex.php?latex=S%5Bi%5D&bg=fff&fg=444444&s=0&c=20201002) . Then we have the recursion formula
. Then we have the recursion formula
![{\rm MIS}(i) = S[i] + \max_{1 \leq j \leq i-1, S[j] < S[i]}\{{\rm MIS}(j)\}](https://s0.wp.com/latex.php?latex=%7B%5Crm+MIS%7D%28i%29+%3D+S%5Bi%5D+%2B+%5Cmax_%7B1+%5Cleq+j+%5Cleq+i-1%2C+S%5Bj%5D+%3C+S%5Bi%5D%7D%5C%7B%7B%5Crm+MIS%7D%28j%29%5C%7D&bg=fff&fg=444444&s=0&c=20201002) , for
, for  and
and ![{\rm MIS}(1) = S[1]](https://s0.wp.com/latex.php?latex=%7B%5Crm+MIS%7D%281%29+%3D+S%5B1%5D&bg=fff&fg=444444&s=0&c=20201002) .
.
The time complexity is  as for each , we spend
as for each , we spend  time to compute it.
time to compute it.
Is there any faster algorithm to solve this problem? The answer is yes. In the following, we describe an algorithm with time complexity  . The algorithm is from here. The key to speed up the algorithm is to compute
. The algorithm is from here. The key to speed up the algorithm is to compute ![\max_{1 \leq j \leq i-1, S[j] < S[i]}\{{\rm MIS}(j)\}](https://s0.wp.com/latex.php?latex=%5Cmax_%7B1+%5Cleq+j+%5Cleq+i-1%2C+S%5Bj%5D+%3C+S%5Bi%5D%7D%5C%7B%7B%5Crm+MIS%7D%28j%29%5C%7D&bg=fff&fg=444444&s=0&c=20201002) within
within  time.
time.
We first describe a slow algorithm, then we show how to use balanced binary search tree to improve the time complexity. Let ![A[1..n]](https://s0.wp.com/latex.php?latex=A%5B1..n%5D&bg=fff&fg=444444&s=0&c=20201002) be an array, whose values are all 0 initially. Define
be an array, whose values are all 0 initially. Define  to be the rank of in the sorted sequence of . At the end of algorithm, the entry
to be the rank of in the sorted sequence of . At the end of algorithm, the entry ![A[j]](https://s0.wp.com/latex.php?latex=A%5Bj%5D&bg=fff&fg=444444&s=0&c=20201002) will contain
will contain  , where
, where  , that is, the rank of
, that is, the rank of ![S[k]](https://s0.wp.com/latex.php?latex=S%5Bk%5D&bg=fff&fg=444444&s=0&c=20201002) is
is  in the sorted sequence of .
in the sorted sequence of .
We now iterate through each element in , and fill up . In  iteration, for , we set
iteration, for , we set ![A[{\rm rank}(i)] \leftarrow S[i] + \max(A[1..{\rm rank}(i)-1])](https://s0.wp.com/latex.php?latex=A%5B%7B%5Crm+rank%7D%28i%29%5D+%5Cleftarrow+S%5Bi%5D+%2B+%5Cmax%28A%5B1..%7B%5Crm+rank%7D%28i%29-1%5D%29&bg=fff&fg=444444&s=0&c=20201002) (note that we might be taking maximum over empty set, and maximum of an empty set is 0 in that case). The value,
(note that we might be taking maximum over empty set, and maximum of an empty set is 0 in that case). The value, ![\max(A[1..n])](https://s0.wp.com/latex.php?latex=%5Cmax%28A%5B1..n%5D%29&bg=fff&fg=444444&s=0&c=20201002) is the final answer.
is the final answer.
Before giving the formal proof, let’s see an example first. Suppose we have the sequence ![S[1..6] = {5,7,4,2,3,8}](https://s0.wp.com/latex.php?latex=S%5B1..6%5D+%3D+%7B5%2C7%2C4%2C2%2C3%2C8%7D&bg=fff&fg=444444&s=0&c=20201002) . After sorting, we get the rank of each element as
. After sorting, we get the rank of each element as ![{\rm Rank}[1..6] = {4,5,3,1,2,6}](https://s0.wp.com/latex.php?latex=%7B%5Crm+Rank%7D%5B1..6%5D+%3D+%7B4%2C5%2C3%2C1%2C2%2C6%7D&bg=fff&fg=444444&s=0&c=20201002) , where
, where ![{\rm Rank}[i]](https://s0.wp.com/latex.php?latex=%7B%5Crm+Rank%7D%5Bi%5D&bg=fff&fg=444444&s=0&c=20201002) is the rank of . One can easily verify this: the rank of
is the rank of . One can easily verify this: the rank of ![S[1]](https://s0.wp.com/latex.php?latex=S%5B1%5D&bg=fff&fg=444444&s=0&c=20201002) , which is 5, is the
, which is 5, is the  element in the sorted sequence
element in the sorted sequence  ; the rank of
; the rank of ![S[2]](https://s0.wp.com/latex.php?latex=S%5B2%5D&bg=fff&fg=444444&s=0&c=20201002) , which is
, which is  , is the
, is the  element in the sorted sequence, and so on.
element in the sorted sequence, and so on.
Initially, the array ![A[1..6] = {0,0,0,0,0,0}](https://s0.wp.com/latex.php?latex=A%5B1..6%5D+%3D+%7B0%2C0%2C0%2C0%2C0%2C0%7D&bg=fff&fg=444444&s=0&c=20201002) .
.

 , so we set
, so we set ![A[4] \leftarrow S[1]](https://s0.wp.com/latex.php?latex=A%5B4%5D+%5Cleftarrow+S%5B1%5D&bg=fff&fg=444444&s=0&c=20201002) . So
. So  becomes
becomes  ;
;

 , we compute
, we compute ![\max(A[1..4])](https://s0.wp.com/latex.php?latex=%5Cmax%28A%5B1..4%5D%29&bg=fff&fg=444444&s=0&c=20201002) to be 5, so we set
to be 5, so we set ![A[5]](https://s0.wp.com/latex.php?latex=A%5B5%5D&bg=fff&fg=444444&s=0&c=20201002) to be
to be ![S[2] + 5](https://s0.wp.com/latex.php?latex=S%5B2%5D+%2B+5&bg=fff&fg=444444&s=0&c=20201002) , which is 12. So becomes
, which is 12. So becomes  ;
;

 , we compute
, we compute ![\max(A[1..2])](https://s0.wp.com/latex.php?latex=%5Cmax%28A%5B1..2%5D%29&bg=fff&fg=444444&s=0&c=20201002) to be 0, so we set
to be 0, so we set ![A[3]](https://s0.wp.com/latex.php?latex=A%5B3%5D&bg=fff&fg=444444&s=0&c=20201002) to be
to be ![S[3]+0 = 4](https://s0.wp.com/latex.php?latex=S%5B3%5D%2B0+%3D+4&bg=fff&fg=444444&s=0&c=20201002) . So becomes
. So becomes  ;
;

 , we compute
, we compute ![\max(A[1..0])](https://s0.wp.com/latex.php?latex=%5Cmax%28A%5B1..0%5D%29&bg=fff&fg=444444&s=0&c=20201002) to be 0 (the maximum of an empty set is 0), so we set
to be 0 (the maximum of an empty set is 0), so we set ![A[1]](https://s0.wp.com/latex.php?latex=A%5B1%5D&bg=fff&fg=444444&s=0&c=20201002) to be
to be ![S[4]+0 = 2](https://s0.wp.com/latex.php?latex=S%5B4%5D%2B0+%3D+2&bg=fff&fg=444444&s=0&c=20201002) . So becomes
. So becomes  ;
;

 , we compute
, we compute ![\max(A[1..1])](https://s0.wp.com/latex.php?latex=%5Cmax%28A%5B1..1%5D%29&bg=fff&fg=444444&s=0&c=20201002) to be 2, so we set
to be 2, so we set ![A[2]](https://s0.wp.com/latex.php?latex=A%5B2%5D&bg=fff&fg=444444&s=0&c=20201002) to be
to be ![S[5]+2 = 5](https://s0.wp.com/latex.php?latex=S%5B5%5D%2B2+%3D+5&bg=fff&fg=444444&s=0&c=20201002) . So becomes
. So becomes  .
.

 , we compute
, we compute ![\max(A[1..5])](https://s0.wp.com/latex.php?latex=%5Cmax%28A%5B1..5%5D%29&bg=fff&fg=444444&s=0&c=20201002) to be 12, so we set
to be 12, so we set ![A[6]](https://s0.wp.com/latex.php?latex=A%5B6%5D&bg=fff&fg=444444&s=0&c=20201002) to be
to be ![S[6]+12 = 20](https://s0.wp.com/latex.php?latex=S%5B6%5D%2B12+%3D+20&bg=fff&fg=444444&s=0&c=20201002) . So becomes
. So becomes  .
.
Hence, the final answer is ![\max(A[1..6]) = 20](https://s0.wp.com/latex.php?latex=%5Cmax%28A%5B1..6%5D%29+%3D+20&bg=fff&fg=444444&s=0&c=20201002) .
.
The correctness of the algorithm is now clear: when we compute , the entry ,  , corresponds to
, corresponds to  if
if  , that is,
, that is, ![S[j]](https://s0.wp.com/latex.php?latex=S%5Bj%5D&bg=fff&fg=444444&s=0&c=20201002) appears before in the input sequence; otherwise, although
appears before in the input sequence; otherwise, although ![S[j] < S[i]](https://s0.wp.com/latex.php?latex=S%5Bj%5D+%3C+S%5Bi%5D&bg=fff&fg=444444&s=0&c=20201002) , we have not encountered yet, so the entry is 0, hence they do not affect the value
, we have not encountered yet, so the entry is 0, hence they do not affect the value ![\max(A[1..{\rm rank}(i)-1])](https://s0.wp.com/latex.php?latex=%5Cmax%28A%5B1..%7B%5Crm+rank%7D%28i%29-1%5D%29&bg=fff&fg=444444&s=0&c=20201002) . Therefore, we are effectively computing
. Therefore, we are effectively computing ![S[i] + \max_{1 \leq j \leq i-1, S[j] < S[i]}\{{\rm MIS}(j)\}](https://s0.wp.com/latex.php?latex=S%5Bi%5D+%2B+%5Cmax_%7B1+%5Cleq+j+%5Cleq+i-1%2C+S%5Bj%5D+%3C+S%5Bi%5D%7D%5C%7B%7B%5Crm+MIS%7D%28j%29%5C%7D&bg=fff&fg=444444&s=0&c=20201002) .
.
The time complexity of the algorithm, is clearly . But it is easy to see how we can improve the time complexity by using balanced binary search tree now: in the computation ![\max\{A[1..i]\}](https://s0.wp.com/latex.php?latex=%5Cmax%5C%7BA%5B1..i%5D%5C%7D&bg=fff&fg=444444&s=0&c=20201002) , we are repeatedly querying the maximum over the range
, we are repeatedly querying the maximum over the range ![[1..i]](https://s0.wp.com/latex.php?latex=%5B1..i%5D&bg=fff&fg=444444&s=0&c=20201002) in the array . We can build a balanced binary search tree for , whose leaves correspond to entries in
in the array . We can build a balanced binary search tree for , whose leaves correspond to entries in ![A[i]](https://s0.wp.com/latex.php?latex=A%5Bi%5D&bg=fff&fg=444444&s=0&c=20201002) , for , and the internal node correspond to the maximum value of all the leaves in the subtree rooted at the internal node. For our example, the root of the balanced binary search tree contains the maximum value of
, for , and the internal node correspond to the maximum value of all the leaves in the subtree rooted at the internal node. For our example, the root of the balanced binary search tree contains the maximum value of ![A[1..6]](https://s0.wp.com/latex.php?latex=A%5B1..6%5D&bg=fff&fg=444444&s=0&c=20201002) , and its left child is in charge of the sub-range
, and its left child is in charge of the sub-range ![A[1..3]](https://s0.wp.com/latex.php?latex=A%5B1..3%5D&bg=fff&fg=444444&s=0&c=20201002) , and its right child is in charge of the sub-range
, and its right child is in charge of the sub-range ![A[4..6]](https://s0.wp.com/latex.php?latex=A%5B4..6%5D&bg=fff&fg=444444&s=0&c=20201002) , and so on. Each leaf corresponds to a degenerated range
, and so on. Each leaf corresponds to a degenerated range ![A[i..i]](https://s0.wp.com/latex.php?latex=A%5Bi..i%5D&bg=fff&fg=444444&s=0&c=20201002) , for
, for  . Both query and update in a balanced binary search tree is (the tree height), hence the time complexity of the algorithm is .
. Both query and update in a balanced binary search tree is (the tree height), hence the time complexity of the algorithm is .
Naturally, to implement this, we can use Fenwick tree.
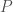 be a set of
be a set of  points in the plane. A block
points in the plane. A block 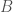 of points in
of points in  -axis. A partition of
-axis. A partition of  , where the blocks are pairwise disjoint, and
, where the blocks are pairwise disjoint, and  . Let
. Let  be the fit of the block
be the fit of the block  , maximizing
, maximizing  (the value
(the value  denotes the optimum partition of the points in
denotes the optimum partition of the points in ![P[1..i]](https://s0.wp.com/latex.php?latex=P%5B1..i%5D&bg=fff&fg=444444&s=0&c=20201002) (the leftmost
(the leftmost 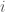 points in
points in  and let
and let  . Then
. Then ![{\rm BestFit}(i+1) = \max_{1 \leq j \leq i+1}\{{\rm BestFit}(j-1) + {\rm fit}(P[j..i+1])\}](https://s0.wp.com/latex.php?latex=%7B%5Crm+BestFit%7D%28i%2B1%29+%3D+%5Cmax_%7B1+%5Cleq+j+%5Cleq+i%2B1%7D%5C%7B%7B%5Crm+BestFit%7D%28j-1%29+%2B+%7B%5Crm+fit%7D%28P%5Bj..i%2B1%5D%29%5C%7D&bg=fff&fg=444444&s=0&c=20201002) . There are totally
. There are totally  can be obtained in
can be obtained in  time for a block, which usually is true (by possibly preprocessing).
time for a block, which usually is true (by possibly preprocessing). is
is , where
, where  . The “best” coefficients
. The “best” coefficients  and
and 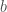 , that is, minimizing
, that is, minimizing  , has closed forms:
, has closed forms: ,
, .
.  of the point set into segment/block, where each segment consists of a subset of
of the point set into segment/block, where each segment consists of a subset of  be the optimum line fitting
be the optimum line fitting  , the cost of the partition is
, the cost of the partition is ,
,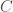 is a positive real number, which encodes the penalty for partitioning
is a positive real number, which encodes the penalty for partitioning  minimizing
minimizing  .
.![{\rm BestFit}(i+1) = \min_{1 \leq j \leq i+1}({\rm fit}(P[j..i+1]) + C + {\rm BestFit}(i))](https://s0.wp.com/latex.php?latex=%7B%5Crm+BestFit%7D%28i%2B1%29+%3D+%5Cmin_%7B1+%5Cleq+j+%5Cleq+i%2B1%7D%28%7B%5Crm+fit%7D%28P%5Bj..i%2B1%5D%29+%2B+C+%2B+%7B%5Crm+BestFit%7D%28i%29%29&bg=fff&fg=444444&s=0&c=20201002) , for
, for  , where
, where ![{\rm fit}(P[j..i+1])](https://s0.wp.com/latex.php?latex=%7B%5Crm+fit%7D%28P%5Bj..i%2B1%5D%29&bg=fff&fg=444444&s=0&c=20201002) is the optimal cost to fit the points in
is the optimal cost to fit the points in ![P[j..i+1]](https://s0.wp.com/latex.php?latex=P%5Bj..i%2B1%5D&bg=fff&fg=444444&s=0&c=20201002) with a single line (we are slightly abusing the notation here).
with a single line (we are slightly abusing the notation here).![{\rm fit}(P[i..j])](https://s0.wp.com/latex.php?latex=%7B%5Crm+fit%7D%28P%5Bi..j%5D%29&bg=fff&fg=444444&s=0&c=20201002) in
in  and
and 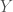 is formed by interspersing the characters into a new string, keeping the characters of
is formed by interspersing the characters into a new string, keeping the characters of ![S_1[1..m]](https://s0.wp.com/latex.php?latex=S_1%5B1..m%5D&bg=fff&fg=444444&s=0&c=20201002) ,
, ![S_2[1..n]](https://s0.wp.com/latex.php?latex=S_2%5B1..n%5D&bg=fff&fg=444444&s=0&c=20201002) and
and ![S[1..n+m]](https://s0.wp.com/latex.php?latex=S%5B1..n%2Bm%5D&bg=fff&fg=444444&s=0&c=20201002) , describe and analyze an algorithm to determine whether
, describe and analyze an algorithm to determine whether  to be true if
to be true if ![S[1..i+j]](https://s0.wp.com/latex.php?latex=S%5B1..i%2Bj%5D&bg=fff&fg=444444&s=0&c=20201002) is a shuffle of
is a shuffle of ![S_1[1..i]](https://s0.wp.com/latex.php?latex=S_1%5B1..i%5D&bg=fff&fg=444444&s=0&c=20201002) and
and ![S_2[i..j]](https://s0.wp.com/latex.php?latex=S_2%5Bi..j%5D&bg=fff&fg=444444&s=0&c=20201002) , and false otherwise, for
, and false otherwise, for  and
and  .
.  . (An empty string is a shuffle of two empty strings).
. (An empty string is a shuffle of two empty strings). , then
, then  is true if and only if the string
is true if and only if the string  .
. , then
, then  is true if and only if the string
is true if and only if the string ![S_2[1..j]](https://s0.wp.com/latex.php?latex=S_2%5B1..j%5D&bg=fff&fg=444444&s=0&c=20201002) is a prefix of the string
is a prefix of the string 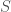 , for
, for  .
.![S_1[i] \neq S_2[j]](https://s0.wp.com/latex.php?latex=S_1%5Bi%5D+%5Cneq+S_2%5Bj%5D&bg=fff&fg=444444&s=0&c=20201002) , then
, then  equals to
equals to  if
if ![S[i+j] = S_1[i]](https://s0.wp.com/latex.php?latex=S%5Bi%2Bj%5D+%3D+S_1%5Bi%5D&bg=fff&fg=444444&s=0&c=20201002) , and
, and  if
if ![S[i+j] = S_2[j]](https://s0.wp.com/latex.php?latex=S%5Bi%2Bj%5D+%3D+S_2%5Bj%5D&bg=fff&fg=444444&s=0&c=20201002) ; otherwise it is false.
; otherwise it is false.![S_1[i] = S_2[j]](https://s0.wp.com/latex.php?latex=S_1%5Bi%5D+%3D+S_2%5Bj%5D&bg=fff&fg=444444&s=0&c=20201002) , then
, then  .
.
 is the final answer.
is the final answer.  , the space complexity is
, the space complexity is  .
.  .
.
 ) algorithm for this problem?
) algorithm for this problem?  , for
, for  , and similarly, for the second random generator, the probability that the randomly generated number
, and similarly, for the second random generator, the probability that the randomly generated number  ,
,  Define two polynomials
Define two polynomials  and
and  . Then consider the multiplication of
. Then consider the multiplication of  :
: ,
, coefficient in the right hand side of the above equation is precisely the probability of
coefficient in the right hand side of the above equation is precisely the probability of  . So the probability that
. So the probability that  is the summation of the first
is the summation of the first  terms. In the problem of interview street, since the distribution is uniform, each
terms. In the problem of interview street, since the distribution is uniform, each  , and each
, and each  . So we can easily obtain the probability that
. So we can easily obtain the probability that  .
.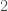 is
is  (the first dice and second dice must both output 1). The probability that the sum is 12 is
(the first dice and second dice must both output 1). The probability that the sum is 12 is  (both dices must output 6). Then consider the probability that the sum is 7: it is at least
(both dices must output 6). Then consider the probability that the sum is 7: it is at least  (the first dice outputs 1, and the second dice outputs 6, or the reverse). But
(the first dice outputs 1, and the second dice outputs 6, or the reverse). But  .
. and let
and let  . Now if the sums 2,3,…,12 comes with the same probability, 1/11, then we have
. Now if the sums 2,3,…,12 comes with the same probability, 1/11, then we have . Now since both
. Now since both  and
and  are polynomials of degree 5,
are polynomials of degree 5,  has real roots; however, the right hand side is a cyclotomic polynomial which does not have any real root. Thus the identity cannot hold.
has real roots; however, the right hand side is a cyclotomic polynomial which does not have any real root. Thus the identity cannot hold.![p_1, ..., p_n \in [0,1]](https://s0.wp.com/latex.php?latex=p_1%2C+...%2C+p_n+%5Cin+%5B0%2C1%5D&bg=fff&fg=444444&s=0&c=20201002) , you want to determine the probability of obtaining exactly
, you want to determine the probability of obtaining exactly ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=fff&fg=444444&s=0&c=20201002) in
in  be the indicator random variable for the event that the result of tossing
be the indicator random variable for the event that the result of tossing  coin is head, for
coin is head, for  .
.  , for
, for  . The probability of obtaining
. The probability of obtaining  . Therefore, the problem is reduced to how fast we can multiply polynomials. Using fast fourier transform, we can multiply two polynomials of degree at most
. Therefore, the problem is reduced to how fast we can multiply polynomials. Using fast fourier transform, we can multiply two polynomials of degree at most  . Hence, we can use divide-and-conquer to multiply these
. Hence, we can use divide-and-conquer to multiply these  .
.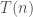 denotes the time to multiply
denotes the time to multiply  ,
, . Hence
. Hence  .
. 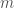 denominations
denominations  , and a target value
, and a target value  , and the target is 122, then the optimum way to pick the denominations is
, and the target is 122, then the optimum way to pick the denominations is  , so the number of bills we need is 5.
, so the number of bills we need is 5. 1’s). W.l.o.g., assume that
1’s). W.l.o.g., assume that  . The recursion formula is the following: define
. The recursion formula is the following: define  to be the smallest number of bills we need to get
to be the smallest number of bills we need to get  , for
, for  . The base cases are:
. The base cases are:  , for
, for  ;
;  for
for  . For
. For  and
and  , if
, if  , then
, then  , where
, where  is the largest index satisfying
is the largest index satisfying  ; otherwise,
; otherwise,  .
. , where
, where 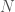 is the target value. So it is a psedu-polynomial time complexity algorithm. The space complexity is
is the target value. So it is a psedu-polynomial time complexity algorithm. The space complexity is  . In the code below, I used “recursion + memoization” approach (the reason is given
. In the code below, I used “recursion + memoization” approach (the reason is given  and
and  in the plane. Suppose we are given the
in the plane. Suppose we are given the  on
on  on
on  to the corresponding point
to the corresponding point  .
. corresponding to
corresponding to  ,
,  , where
, where  is the set of segments in
is the set of segments in  , so that they are ordered from left to right, and we also renumber the corresponding indices of
, so that they are ordered from left to right, and we also renumber the corresponding indices of  to
to  to
to 